
Investigadores del MIT desarrollan herramienta de IA que compara imágenes en 3D




Fecha: 05/07/2018
Procedencia: MediMaging
Web: ver aquí
a
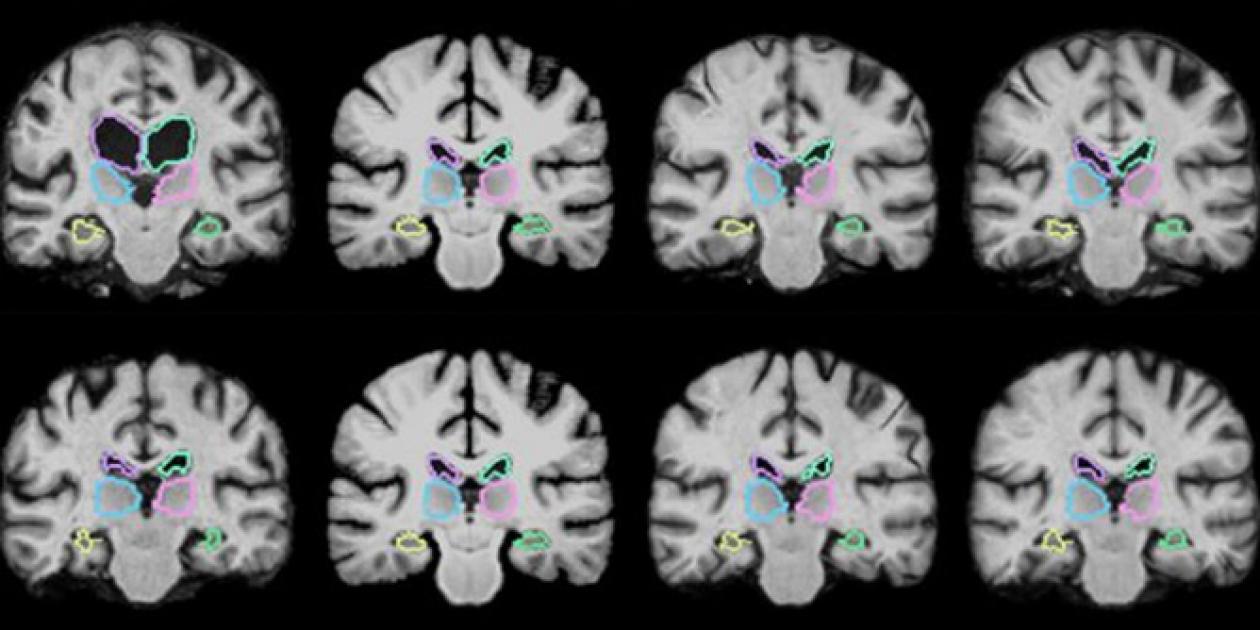
Un equipo de investigadores del Instituto Tecnológico de Massachusetts (Cambridge, MA, EUA) presentó un par de documentos de conferencia que describen un algoritmo de aprendizaje automático que puede registrar los exámenes cerebrales y otras imágenes en 3D, más de 1.000 veces más rápido usando nuevas técnicas de aprendizaje. El algoritmo funciona mientras registra miles de pares de imágenes y adquiere información durante este proceso sobre cómo alinear las imágenes y calcular algunos parámetros de alineación óptimos. Después del entrenamiento, el algoritmo usa esos parámetros para asignar todos los píxeles de una imagen a otra simultáneamente. Esto reduce el tiempo de registro a uno o dos minutos usando una computadora normal, o a menos de un segundo usando una GPU con una exactitud similar a la de los sistemas más avanzados.
Con el fin de analizar las variaciones en las estructuras cerebrales en pacientes con una enfermedad o condición particular, los neurocientíficos usan frecuentemente la técnica de registro de imágenes médicas. Esto implica la superposición de dos imágenes, como las imágenes de resonancia magnética (RM), para comparar y analizar las diferencias anatómicas en gran detalle. Sin embargo, este proceso generalmente demora dos horas o más, ya que los sistemas tradicionales alinean meticulosamente cada uno de los potencialmente millones de píxeles en los escaneos combinados. Dado que los exámenes de resonancia magnética son básicamente cientos de imágenes en 2D apiladas que forman imágenes tridimensionales masivas, llamadas “volúmenes”, que contienen un millón o más de píxeles en 3D, llamados “vóxeles”, puede ser muy laborioso alinear todos los vóxeles en el primer volumen con aquellos en el segundo. Además, los escaneos provenientes de diferentes máquinas y con diferentes orientaciones espaciales pueden hacer que la coincidencia de los vóxeles sea un proceso aún más complejo desde el punto de vista computacional.
El algoritmo de los investigadores llamado VoxelMorph está impulsado por una red neuronal convolucional (CNN), un método de aprendizaje automático comúnmente utilizado para el procesamiento de imágenes. Estas redes consisten en varios nodos que procesan imágenes y otra información a través de varias capas de computación. Los investigadores entrenaron su algoritmo en 7.000 exámenes de resonancia magnética del cerebro disponibles públicamente y luego lo probaron en 250 exámenes adicionales. Durante el entrenamiento, los investigadores alimentaron los exámenes cerebrales en el algoritmo por parejas. Usando una CNN y una capa de computación modificada llamada transformador espacial, el método captura las similitudes de los vóxeles en una resonancia magnética con los vóxeles en la otra exploración. Esto permite que el algoritmo obtenga información sobre grupos de vóxeles, como las formas anatómicas comunes a ambos exámenes, que utiliza para calcular parámetros optimizados que se pueden aplicar a cualquier par de exámenes.
Cuando se introducen dos nuevos exámenes en el algoritmo, una función matemática simple usa esos parámetros optimizados para calcular rápidamente la alineación exacta de cada vóxel en ambos exámenes. Por lo tanto, el componente CNN del algoritmo obtiene toda la información necesaria durante el entrenamiento de modo que, durante cada nuevo registro, el registro completo se puede ejecutar usando una evaluación de función fácilmente computable. Los investigadores descubrieron que su algoritmo podía registrar con exactitud todos sus 250 escáneres cerebrales de prueba, aquellos registrados después del conjunto de entrenamiento, en dos minutos usando una unidad de procesamiento central tradicional y en menos de un segundo usando una unidad de procesamiento de gráficos. Lo que es particularmente notable es que el algoritmo es “no supervisado”, lo que significa que no requiere información adicional aparte de los datos de las imágenes. Algunos algoritmos de registro incorporan modelos CNN pero requieren una “verdad fundamental”, lo que significa que otro algoritmo tradicional se ejecuta primero para calcular registros exactos. Sin embargo, el algoritmo desarrollado por los investigadores del MIT mantiene su exactitud sin necesidad de esos datos.
Además de analizar exámenes cerebrales, el algoritmo veloz podría encontrar una amplia gama de posibles aplicaciones, según los investigadores. Por ejemplo, otros investigadores en el MIT actualmente usan el algoritmo en imágenes de los pulmones. El algoritmo también podría permitir el registro de imágenes durante las operaciones y permitir a los cirujanos registrar potencialmente los exámenes casi en tiempo real, obteniendo una imagen mucho más clara del progreso de la cirugía.
“Este es un caso donde un cambio cuantitativo suficientemente grande [de registro de imágenes] - de horas a segundos - se convierte en uno cualitativo, abriendo nuevas posibilidades como ejecutar el algoritmo durante un examen mientras el paciente aún está en el escáner, habilitando la toma de decisiones clínicas sobre qué tipos de datos se deben adquirir y en qué parte del cerebro se debe enfocar sin obligar al paciente a volver días o semanas después “, dijo Bruce Fischl, profesor de radiología en la Facultad de Medicina de Harvard y neurocientífico en el Hospital General de Massachusetts. Los artículos fueron presentados por los investigadores del MIT en la Conferencia sobre Visión Computacional y Reconocimiento de Patrones (CVPR) y en la Conferencia de Informática Médica e Intervenciones Asistidas por Computadora (MICCAI).
Para poder escribir un comentario debe iniciar sesión o darse de alta en el portal.

























